常用技巧
- 避免构造不必要的对象,例如 std::string
- 函数返回值为常量字符串时,且需要 std::string_view 类型;函数返回值类型可以设为 std::string_view,如果设为 std::string,会有多余的拷贝。
分支预测 & unlikely
ref:https://www.zhihu.com/question/639443238
避免反复构造和析构 vector
【热点】
问题来源于 YMatrix 实习,下面的 vector 声明在了 for 循环内部,每次遍历都会进行构造和析构,成本较大。
1 | for (std::size_t i = 0; i < times; ++i) { |
【优化】
可以将 vector 声明位置提到 for 循环外部,每次遍历对 vector 进行 clear 即可
1 | std::vector<std::uint32_t> idx_chain; |
vector 使用 reserve 避免重复内存申请与数据复制
场景介绍
当使用 vector 时,如果已知需要多少元素的空间,则使用 reserve 函数预先分配足够的内存空间,减少动态内存分配和元素复制的次数。这使得插入操作更加高效,尤其是在处理大量数据时,性能优势更加明显。
代码验证
【链接】https://quick-bench.com/q/ctDLCeIqzoycLX9KUuBajAapaUA
-
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
using namespace std;
constexpr int SIZE = 10000;
int vector_push_back_one_by_one() {
std::vector<std::string> str_vec;
for (int i = 0; i < SIZE; i++) {
str_vec.push_back(std::to_string(i));
}
return 0;
}
int vector_push_back_reserve() {
std::vector<std::string> str_vec;
str_vec.reserve(SIZE);
for (int i = 0; i < SIZE; i++) {
str_vec.push_back(std::to_string(i));
}
return 0;
}
static void PushOneByOne(benchmark::State& state) {
// Code inside this loop is measured repeatedly
for (auto _ : state) {
auto ret = vector_push_back_one_by_one();
// Make sure the variable is not optimized away by compiler
benchmark::DoNotOptimize(ret);
}
}
// Register the function as a benchmark
BENCHMARK(PushOneByOne);
static void PushReserve(benchmark::State& state) {
// Code before the loop is not measured
for (auto _ : state) {
auto ret = vector_push_back_reserve();
// Make sure the variable is not optimized away by compiler
benchmark::DoNotOptimize(ret);
}
}
BENCHMARK(PushReserve);
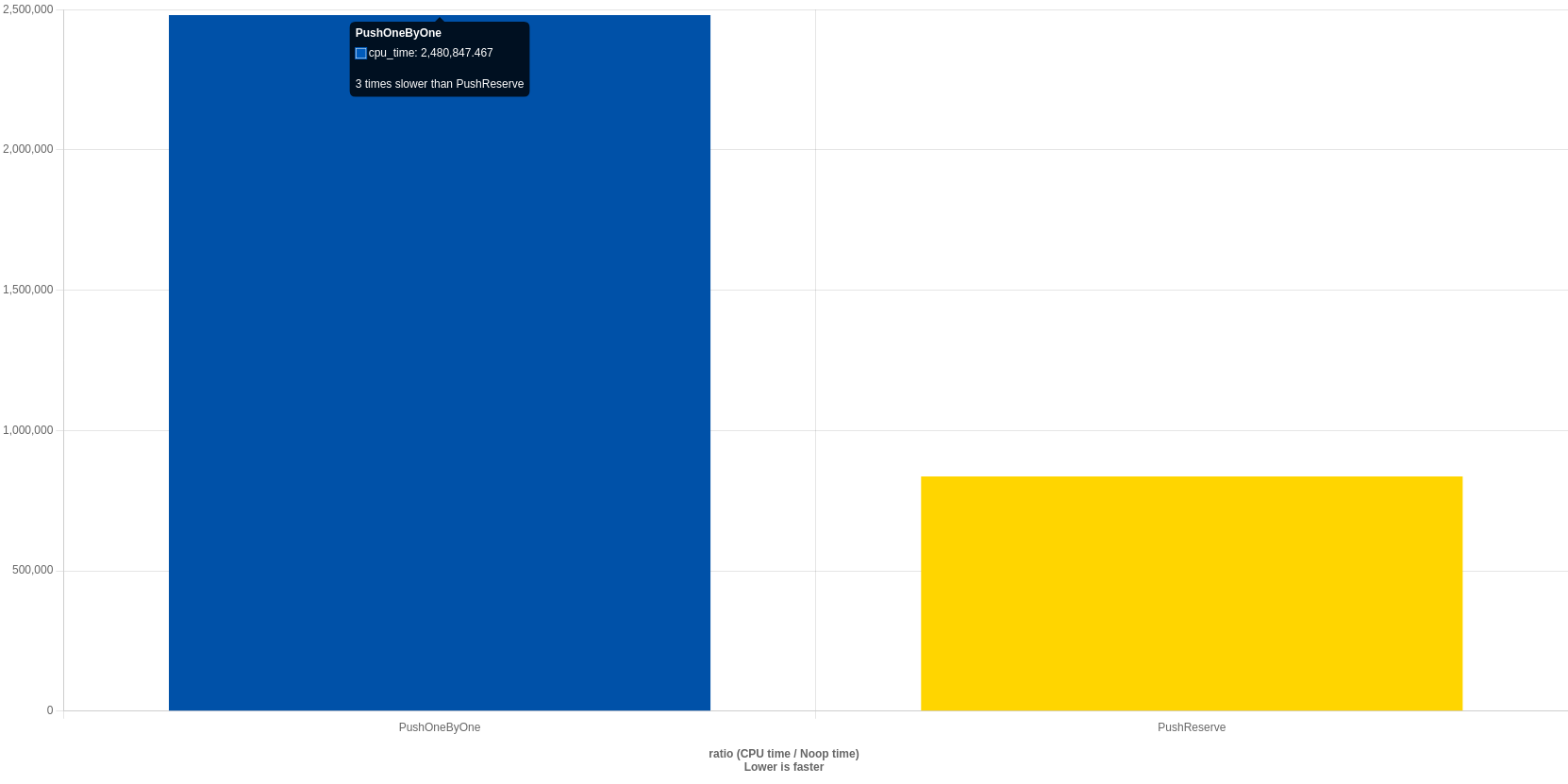
GPT 现象解释
vector_push_back_reserve 函数比 vector_push_back_one_by_one 函数高效的原因主要在于内存分配策略的不同。
vector_push_back_one_by_one 函数
- 动态内存分配:
std::vector的push_back方法会在容器容量不足时,自动分配新的内存来存储更多的元素。每次分配的内存大小通常是当前容量的两倍左右(具体策略因标准库实现而异)。例如,初始容量可能为 0,第一次调用push_back时分配一定大小的内存(如 16 个元素的空间),当插入第 17 个元素时,会重新分配内存(如 32 个元素的空间),并将原有元素复制到新的内存空间中,然后释放旧的内存空间。 - 多次内存分配和复制:在插入大量元素时,这种动态内存分配会导致多次内存分配和复制操作。每次重新分配内存时,都需要将已有的元素复制到新的内存空间中,这会消耗大量的时间和计算资源。随着元素数量的增加,这种开销会逐渐累积,导致整体性能下降。
vector_push_back_reserve 函数
- 预先分配内存:
std::vector的reserve方法允许在容器创建时预先分配足够的内存来存储指定数量的元素。在vector_push_back_reserve函数中,通过调用str_vec.reserve(SIZE),预先分配了足够存储SIZE个std::string元素的内存空间。 - 减少内存分配和复制:由于预先分配了足够的内存,后续调用
push_back方法时,不需要再进行动态内存分配和元素复制操作。所有元素都可以直接插入到预先分配的内存空间中,从而避免了多次内存分配和复制的开销,显著提高了插入操作的效率。
性能对比
- 时间复杂度:
vector_push_back_one_by_one的时间复杂度为 O(nlogn),因为每次重新分配内存时,都需要复制已有的元素,而复制操作的时间复杂度与当前元素数量成正比。相比之下,vector_push_back_reserve的时间复杂度为 O(n),因为所有元素都可以直接插入到预先分配的内存空间中,无需额外的复制操作。 - 实际性能:在实际运行中,
vector_push_back_reserve函数的执行时间通常比vector_push_back_one_by_one函数短得多,尤其是在插入大量元素时。这是因为vector_push_back_one_by_one函数需要进行多次内存分配和复制操作,而vector_push_back_reserve函数只需要一次内存分配,后续的插入操作非常高效。
unordered_map 替换 map
问题
问题来自与 cmu 15-445 fall 2022 p1,当时在线测试HardTest_4 超时(上限是 10s,当时程序耗时 14s)。
调优
在 macbook 上跑的项目,没有 perf 分析工具,使用 macos 中的 Instruments 进行分析。
可以看到 HardTest_4 的主要耗时在 HistoryCmpLess() 函数上:
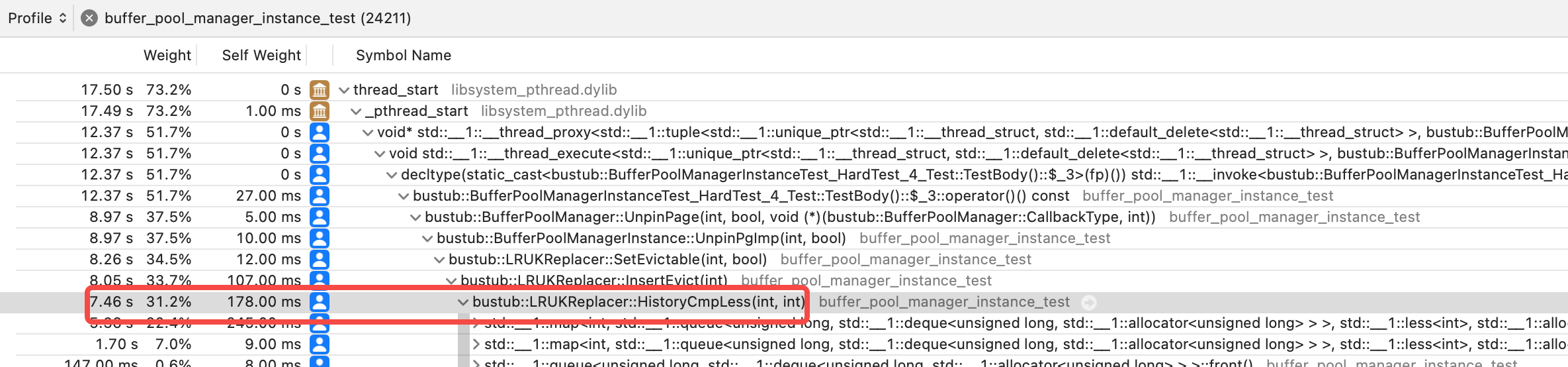
耗时集中在下面三行代码,推测是 history_ 的随机取数据导致性能低下。
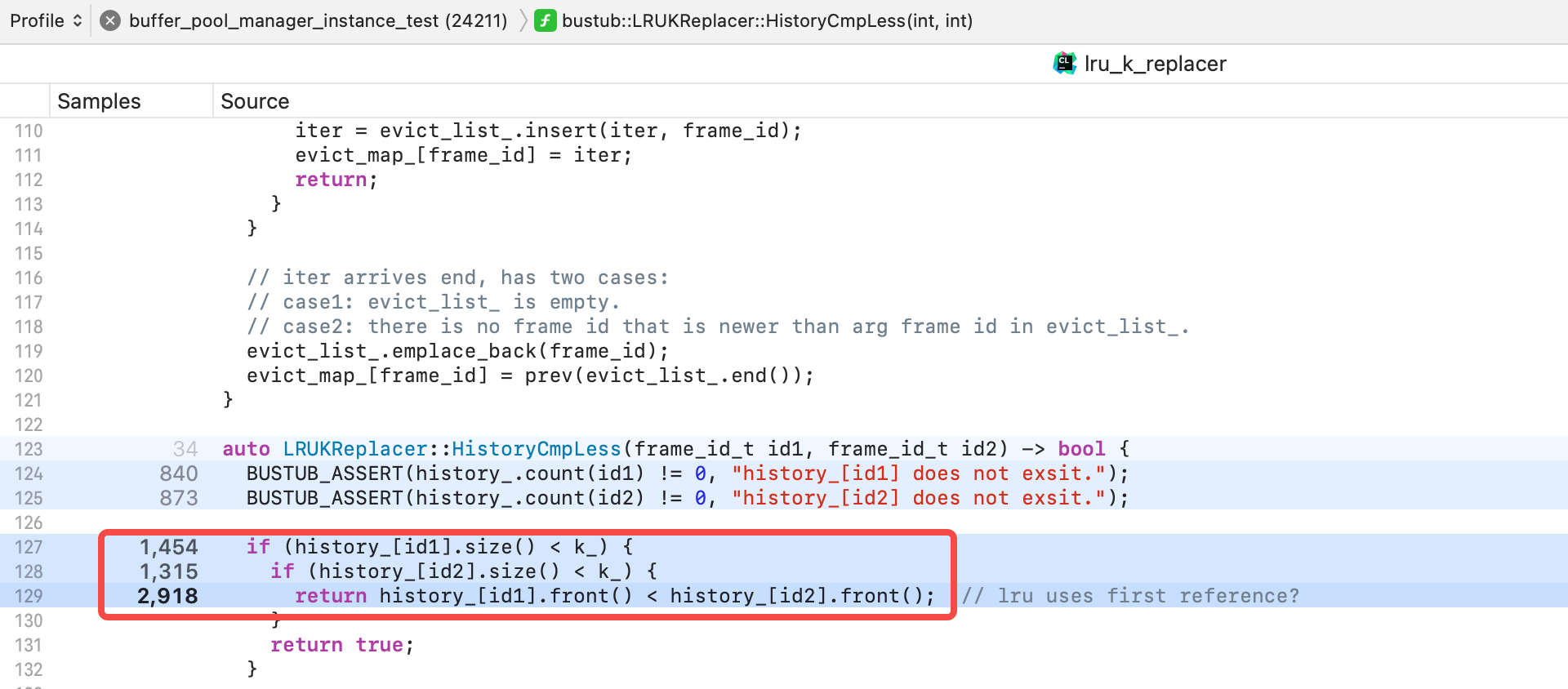
查看 history_ 类型,果然是 map 类型,但是使用 unordered_map 更加高效。更换数据类型后,耗时下降到 7s,符合预期。